UIS Cannot obtain the Onestor did file
- 0 Followed
- 0Collected ,2791Browsed

Network Topology
Null
Problem Description
UIS is missing the onestor information for a hot backup host when obtaining host info.
Process Analysis
1.
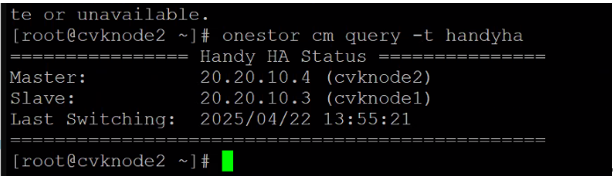
2.
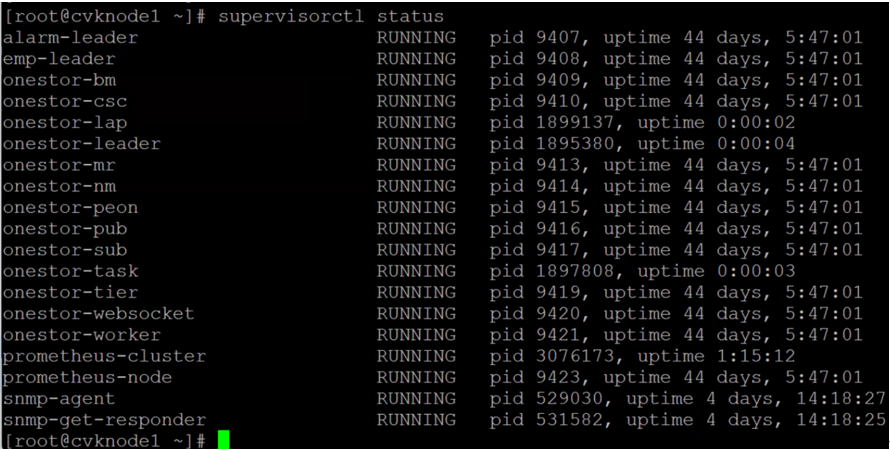
3.
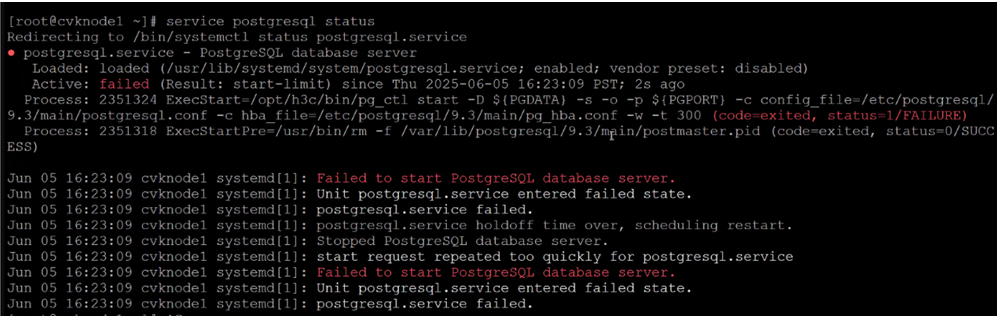
4.
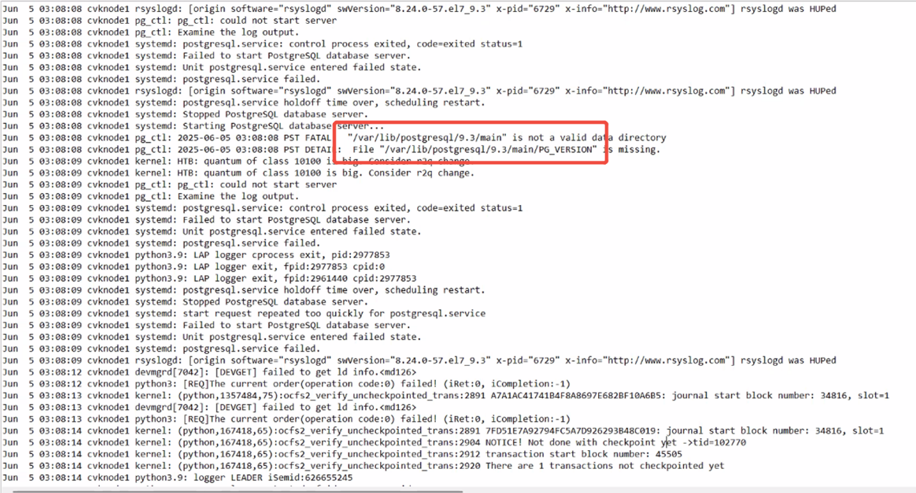
5.
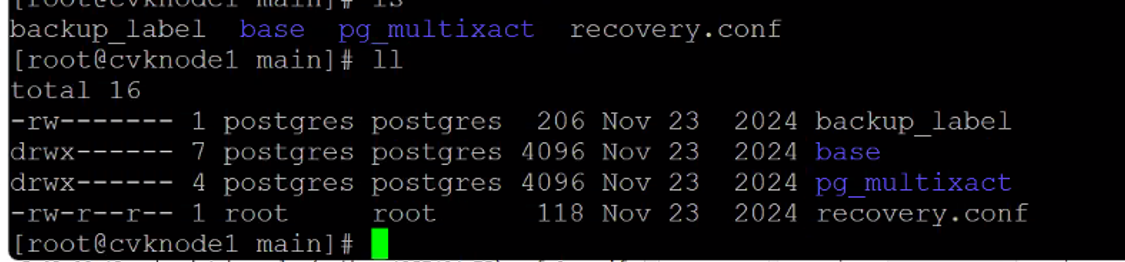
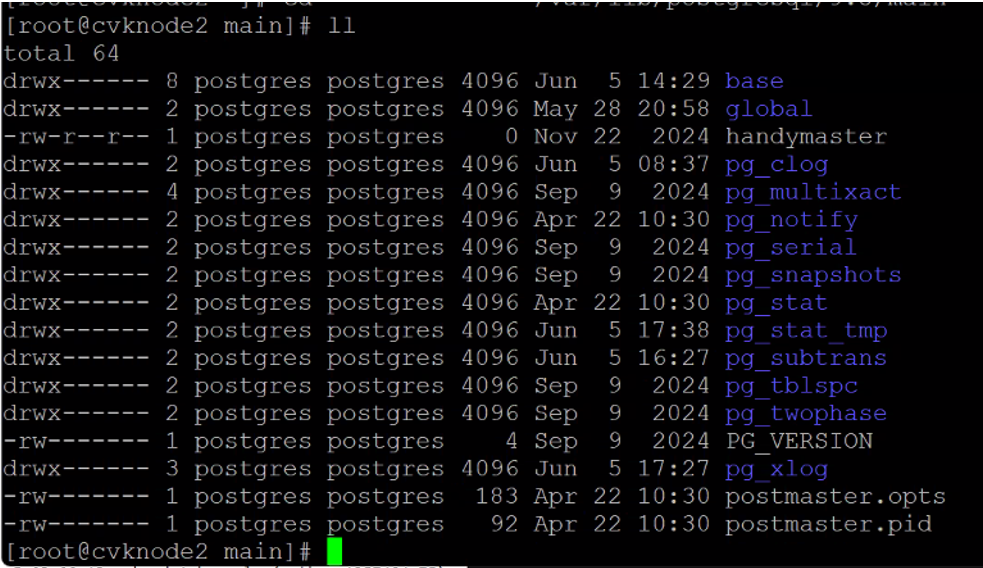
6.

7.
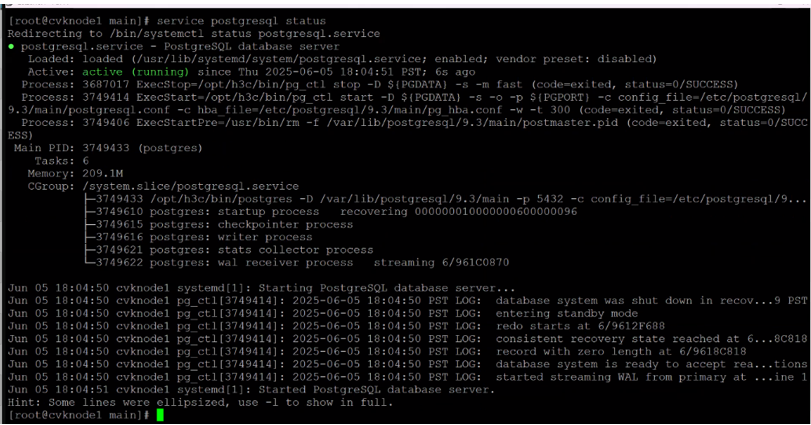
8.
Solution
The missing configuration file in the main folder of the Postgres process caused the continuous restarting of the process; refer to the above procedure for the fix.